Vanna 公积金行业 Text-to-SQL 投喂数据方案
一、总体方案
这份方案用于指导公积金行业的 Vanna 训练落地。整体思路是:
第一阶段:先投喂实体表,让模型认识真实库表、字段、业务口径和基础 SQL 写法。
第二阶段:再按错题和高频复杂场景整理业务视图,用视图固化难以稳定表达的关联关系和指标口径。也就是说,方案不是一开始就把所有业务都做成视图,也不是直接把全库原始表一次性导入。第一阶段先把核心实体表的 DDL、Documentation、SQL 问答对投喂完整,形成基础能力;第二阶段根据回归测试和错题结果,再判断哪些关联、指标或复杂查询需要用视图封装。
这个顺序的原因:
- 实体表训练能保留真实库表结构,便于模型理解系统原貌。
- 文档可以先描述表关系、字段含义、指标口径和默认过滤条件。
- SQL 问答对可以先覆盖常见查询写法。
- 如果表关联关系靠文档和 SQL 样例仍然不稳定,再通过视图把 Join、过滤、状态翻译和指标算法写死。
- 视图只针对高频、复杂、易错场景建设,避免一开始产生大量难维护的视图。
二、上线交付物与公司内部资产
上线交付只需要 Vanna 本身:只要目标 Vanna 实例中已经导入训练数据,并且通过回归验证,就具备上线交付条件。业务建模材料、错题集、训练记录属于公司 Git 内部资产,用于后续维护和复盘,不作为对外交付产物。
| 类别 | 内容 | 是否导入 Vanna | 是否作为上线交付产物 | 说明 |
|---|---|---|---|---|
| 上线交付内容 | 实体表 DDL / DDL-schema | 是 | 是 | 第一阶段导入,覆盖核心实体表结构 |
| 上线交付内容 | Documentation | 是 | 是 | 第一阶段导入,覆盖字段解释、表关系、指标口径、业务规则 |
| 上线交付内容 | SQL 问答对 | 是 | 是 | 第一阶段导入,覆盖高频问题和标准 SQL |
| 上线交付内容 | 视图 DDL / 视图说明 / 视图 SQL 问答对 | 是 | 需要时交付 | 第二阶段只针对复杂、易错、高频场景导入 |
| 公司 Git 内部资产 | 业务建模材料 | 否 | 否 | 包括业务域范围、核心实体表清单、字段解释、状态枚举、表关系说明、指标口径、时间规则、高频问题清单 |
| 公司 Git 内部资产 | 错题集 | 否 | 否 | 记录测试问题、错误 SQL、错误原因、修正动作和复测结果 |
| 公司 Git 内部资产 | 训练记录 | 否 | 否 | 记录每轮导入内容、回归结果、遗留问题和版本变化 |
这里要特别注意:业务建模材料、错题集、训练记录都不直接导入 Vanna,也不作为上线交付产物。真正导入 Vanna 的,是从业务建模材料和错题中整理出来的训练数据,例如 Documentation、SQL 问答对、实体表 DDL 或视图 DDL。
公司 Git 中建议至少保留两份内部维护文档:
01_错题集.md
02_训练记录.md业务建模材料也需要保存到公司 Git,可以独立保存为 00_业务建模材料.md,也可以作为 02_训练记录.md 的前置章节或附件保存。它同样不作为上线交付文件。
导入 Vanna 的 DDL、Documentation、SQL 问答对可以在训练记录里登记或作为附件保存,但训练记录文件本身不作为训练数据导入 Vanna。
三、Vanna 训练入口与录入类型
内部 Vanna 地址:
10.99.6.113:8097内部使用说明文档位置:
生产贝贝 / 共享文档 / 科技创新与产品研发... / 17-成果物管理-研发... / 00-工具 / 23-Vanna / vanna部署及使用资料贝贝共享文档位置截图如下,用于快速定位 Vanna 部署及使用资料:

重点查看:
(2) 关于 text2sql 知识库模板的作用与规范Vanna 增加训练数据入口如下:
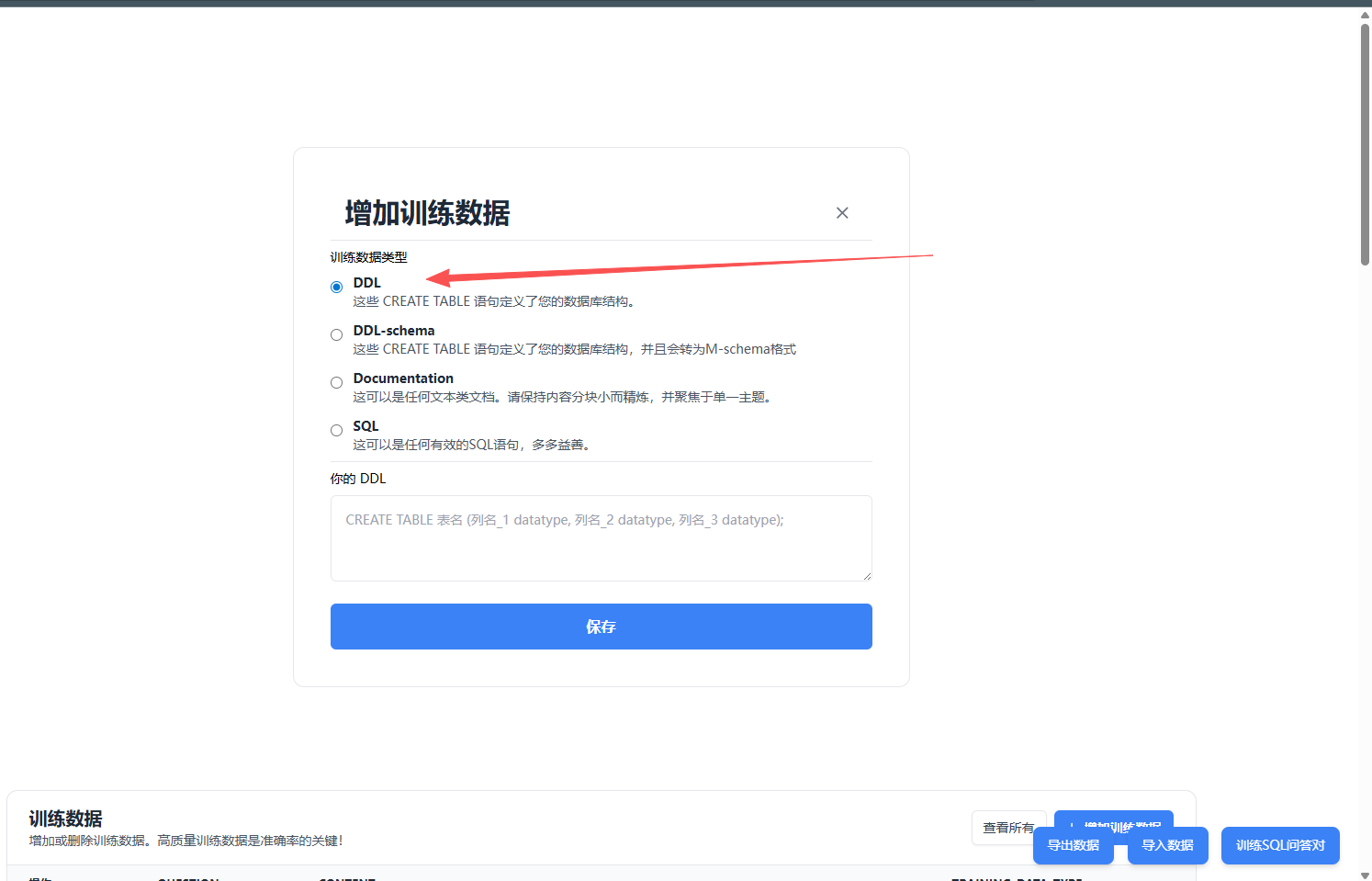
训练数据类型选择建议:
| 类型 | 适合内容 | 使用建议 |
|---|---|---|
DDL | 单张实体表、单个视图的完整 CREATE TABLE / CREATE VIEW | 单个对象内容较完整时使用 |
DDL-schema | 多张实体表或多张视图的批量 DDL | 批量导入时优先使用,Vanna 会拆成更适合检索的 schema 文档 |
Documentation | 业务规则、指标口径、字段解释、逻辑表关系、时间规则 | 第一阶段必须补充,不要只投喂 DDL |
SQL | 标准 SQL、Question-SQL Pair | 高频问题和复杂查询必须沉淀 |
DDL 与 DDL-schema 的区别:
| 类型 | 处理方式 | 风险 | 推荐用法 |
|---|---|---|---|
DDL | 把输入的 CREATE TABLE / CREATE VIEW 作为一个或几个训练块保存 | 表多时训练块过大,检索时容易带出不相关内容 | 单表、单视图、单个主题对象 |
DDL-schema | 将多张表或多张视图转换成更细的 schema 文档 | 需要保证 DDL 本身干净、字段注释清楚 | 多表、多视图批量导入 |
四、第一阶段:实体表训练
第一阶段的目标是让 Vanna 先理解真实数据库中的核心实体表。这个阶段先不急着建业务视图,而是把实体表结构、字段语义、表关系、业务口径和基础 SQL 问答对投喂完整。
4.1 准备业务建模材料并选择核心实体表
第一阶段不是直接打开 Vanna 粘贴 DDL,而是先准备业务建模材料。业务建模材料用于回答“本轮训练什么、为什么训练这些表、这些字段是什么意思、表之间怎么关联、指标怎么算”。
第一阶段至少准备以下材料:
| 材料 | 内容 | 后续去向 |
|---|---|---|
| 业务域范围 | 本轮训练缴存、提取、贷款还是归集 | 写入训练记录,不直接投喂 |
| 核心实体表清单 | 表名、中文名、业务含义、是否进入本轮训练 | 写入训练记录,不直接投喂 |
| 字段解释 | 字段名、中文含义、是否敏感、常见取值 | 整理成 Documentation 投喂 |
| 表关系说明 | 实体表之间的逻辑关联字段 | 整理成 Documentation 投喂 |
| 状态枚举 | 状态码与中文含义 | 整理成 Documentation 投喂 |
| 指标口径 | 缴存额、人数、单位数、余额等算法 | 整理成 Documentation 和 SQL 问答对 |
| 高频问题清单 | 业务真实问法和期望结果 | 整理成 SQL 问答对 |
不要一次性投喂全库。建议先按业务域选择核心实体表。
| 业务域 | 核心实体表示例 | 说明 |
|---|---|---|
| 缴存 | 单位信息表、个人账户表、缴存流水表 | 覆盖单位、个人、缴存记录 |
| 提取 | 提取申请表、提取明细表、审批记录表 | 覆盖申请、金额、原因、状态 |
| 贷款 | 贷款申请表、贷款发放表、还款流水表、贷款余额表 | 覆盖发放、还款、余额、逾期 |
| 归集 | 资金流水表、账户余额表、业务渠道表 | 覆盖资金流入流出和渠道 |
第一轮建议只选择一个业务域,例如先做缴存。缴存跑通后,再复制方法到提取、贷款。
4.2 投喂实体表 DDL
实体表 DDL 要尽量完整,包括字段名、字段类型、主键、索引、字段注释。如果原始 DDL 没有注释,至少要在 Documentation 中补齐字段解释。
示例:
CREATE TABLE t_dw_info (
dwzh VARCHAR(32) PRIMARY KEY,
dwmc VARCHAR(200),
dwdz VARCHAR(500),
dwzt VARCHAR(10),
khny VARCHAR(6)
);
CREATE TABLE t_gr_info (
grzh VARCHAR(32) PRIMARY KEY,
dwzh VARCHAR(32),
xm VARCHAR(100),
zjhm VARCHAR(50),
grzhzt VARCHAR(10),
khny VARCHAR(6)
);
CREATE TABLE t_jc_ls (
id BIGINT PRIMARY KEY,
grzh VARCHAR(32),
ym VARCHAR(6),
grjcjs DECIMAL(18, 2),
dwjcbl DECIMAL(8, 4),
grjcbl DECIMAL(8, 4),
dwyjc DECIMAL(18, 2),
gryjc DECIMAL(18, 2),
jcrq DATE,
is_deleted INTEGER
);录入建议:
- 单张表调试时用
DDL。 - 同一个业务域多张表批量导入时用
DDL-schema。 - 每次导入后,在训练记录里登记表名、业务域、导入时间、导入人。
4.3 投喂实体表 Documentation
Documentation 要解决 DDL 解决不了的问题,包括字段中文含义、逻辑关联、状态枚举、指标口径、时间规则和默认过滤条件。
示例:
[缴存][DOC] 实体表说明
t_dw_info 是单位信息表,记录缴存单位基础信息。
t_gr_info 是个人账户表,记录职工个人公积金账户信息。
t_jc_ls 是缴存流水表,记录每月缴存入账明细。
[缴存][DOC] 表关系说明
t_dw_info.dwzh = t_gr_info.dwzh,表示单位与个人账户的所属关系。
t_gr_info.grzh = t_jc_ls.grzh,表示个人账户与缴存流水的关联关系。
[缴存][DOC] 状态字段说明
t_gr_info.grzhzt = '1' 表示正常。
t_gr_info.grzhzt = '2' 表示封存。
t_gr_info.grzhzt = '3' 表示销户。
[缴存][DOC] 指标口径
缴存额、月缴存额、汇缴金额默认指单位月缴存额与个人月缴存额之和。
缴存总额 = SUM(t_jc_ls.dwyjc + t_jc_ls.gryjc)。
缴存人数 = COUNT(DISTINCT t_gr_info.grzh)。
缴存单位数 = COUNT(DISTINCT t_dw_info.dwzh)。
[缴存][DOC] 默认规则
除非用户明确要求历史、作废或删除数据,否则默认 t_jc_ls.is_deleted = 0。
用户提到某个单位名称时,使用 t_dw_info.dwmc 进行模糊匹配。
用户提到“今年”“本年”时,默认使用当前自然年度。
用户提到“上月”时,默认使用当前日期的上一个自然月。第一阶段的关键点是:先尝试用文档把表关系讲清楚。只要模型能稳定按文档生成正确 Join,就不需要立刻建视图。
4.4 投喂实体表 SQL 问答对
SQL 问答对用于沉淀高频问题和复杂查询写法。第一阶段的 SQL 应该直接基于实体表写,目的是让模型学习真实表之间怎么关联。
示例 1:
问题:全市上个月缴存金额排名前十的单位有哪些?
说明:示例以 2026-05-09 作为测试日期,上月为 202604。SELECT
dw.dwzh AS 单位账号,
dw.dwmc AS 单位名称,
SUM(jc.dwyjc + jc.gryjc) AS 总缴存额
FROM t_dw_info dw
JOIN t_gr_info gr ON dw.dwzh = gr.dwzh
JOIN t_jc_ls jc ON gr.grzh = jc.grzh
WHERE jc.is_deleted = 0
AND jc.ym = '202604'
GROUP BY dw.dwzh, dw.dwmc
ORDER BY 总缴存额 DESC
LIMIT 10;示例 2:
问题:某某公司今年一共缴了多少钱?
说明:示例以 2026-05-09 作为测试日期,统计 2026 自然年。SELECT
dw.dwzh AS 单位账号,
dw.dwmc AS 单位名称,
SUM(jc.dwyjc + jc.gryjc) AS 总缴存额
FROM t_dw_info dw
JOIN t_gr_info gr ON dw.dwzh = gr.dwzh
JOIN t_jc_ls jc ON gr.grzh = jc.grzh
WHERE jc.is_deleted = 0
AND dw.dwmc LIKE '%某某公司%'
AND jc.jcrq >= '2026-01-01'
AND jc.jcrq < '2027-01-01'
GROUP BY dw.dwzh, dw.dwmc
ORDER BY 总缴存额 DESC;示例 3:
问题:今年以来缴存总额比去年同期增长多少?
说明:示例以 2026-05-09 作为测试日期,统计到 2026-05-01 之前。WITH current_period AS (
SELECT SUM(jc.dwyjc + jc.gryjc) AS 缴存总额
FROM t_jc_ls jc
WHERE jc.is_deleted = 0
AND jc.jcrq >= '2026-01-01'
AND jc.jcrq < '2026-05-01'
),
last_period AS (
SELECT SUM(jc.dwyjc + jc.gryjc) AS 缴存总额
FROM t_jc_ls jc
WHERE jc.is_deleted = 0
AND jc.jcrq >= '2025-01-01'
AND jc.jcrq < '2025-05-01'
)
SELECT
current_period.缴存总额 AS 今年缴存总额,
last_period.缴存总额 AS 去年同期缴存总额,
current_period.缴存总额 - last_period.缴存总额 AS 增长额,
ROUND(
(current_period.缴存总额 - last_period.缴存总额)
/ NULLIF(last_period.缴存总额, 0) * 100,
2
) AS 增长率
FROM current_period, last_period;4.5 第一阶段验收标准
第一阶段完成后,至少要验证:
- Vanna 能正确识别核心实体表。
- Vanna 能根据 Documentation 理解字段含义和状态枚举。
- Vanna 能按文档中的逻辑关系生成正确 Join。
- Vanna 能稳定生成常见统计、排名、明细查询 SQL。
- 高频问题可以直接用实体表 SQL 正确回答。
如果这些目标能达到,就可以继续补更多实体表和问答对;如果频繁出现表关系、Join、指标口径错误,就进入第二阶段做视图整理。
五、第二阶段:针对性视图整理
第二阶段不是替代第一阶段,而是在第一阶段的基础上做治理。只有当文档说明和 SQL 问答对仍然无法让模型稳定生成正确 SQL 时,才需要把复杂逻辑封装成视图。
5.1 什么时候需要建视图
出现以下情况时,建议整理业务视图:
| 场景 | 表现 | 处理方式 |
|---|---|---|
| Join 链路长 | 一个问题经常需要 4 张以上表关联 | 用视图固定 Join |
| 表关系容易错 | 文档写了关联关系,但模型仍然连错表或漏表 | 用视图封装正确关联 |
| 指标口径复杂 | 一个指标涉及多字段相加、状态过滤、时间规则 | 在视图中预处理指标字段 |
| 状态翻译复杂 | 业务状态码多,模型经常理解错 | 在视图中转成业务可读字段 |
| 默认过滤条件多 | 删除标记、作废状态、测试数据经常漏过滤 | 在视图中统一过滤 |
| 高频查询重复 | 大量问题都复用同一段 Join 和过滤逻辑 | 用视图减少重复 SQL |
| 敏感字段需要隔离 | 原表包含身份证号、手机号、银行卡号 | 视图只暴露必要字段 |
简单说:表关联关系能靠 Documentation 和 SQL 样例稳定实现,就先不建视图;实现不了或不稳定,再通过视图写好。
5.2 视图设计原则
- 一个视图只服务一个清晰业务主题,例如缴存明细、提取申请、贷款发放、贷款回收。
- 视图字段尽量贴近业务提问,例如单位名称、个人账号、汇缴月份、月缴存额、贷款余额。
- 在视图中固定 Join、默认过滤、状态翻译和常用指标。
- 不把所有字段都塞进视图,只暴露问数场景需要的字段。
- 不暴露身份证号、手机号、银行卡号等敏感字段。
- 视图名称要能体现业务主题,例如
v_缴存业务明细宽表。 - 视图建好后,要同步投喂视图 DDL、视图 Documentation 和视图 SQL 问答对。
5.3 视图示例
当第一阶段中 t_dw_info、t_gr_info、t_jc_ls 的关联经常出错时,可以整理缴存业务明细视图。
CREATE VIEW v_缴存业务明细宽表 AS
SELECT
dw.dwzh AS 单位账号,
dw.dwmc AS 单位名称,
gr.grzh AS 个人账号,
gr.xm AS 职工姓名,
jc.ym AS 汇缴月份,
jc.grjcjs AS 缴存基数,
jc.dwjcbl AS 单位缴存比例,
jc.grjcbl AS 个人缴存比例,
jc.dwyjc AS 单位月缴存额,
jc.gryjc AS 个人月缴存额,
(jc.dwyjc + jc.gryjc) AS 月缴存额,
CASE
WHEN gr.grzhzt = '1' THEN '正常'
WHEN gr.grzhzt = '2' THEN '封存'
WHEN gr.grzhzt = '3' THEN '销户'
ELSE '其他'
END AS 个人账户状态,
jc.jcrq AS 实际入账日期
FROM t_dw_info dw
JOIN t_gr_info gr ON dw.dwzh = gr.dwzh
JOIN t_jc_ls jc ON gr.grzh = jc.grzh
WHERE jc.is_deleted = 0;配套 Documentation:
[缴存][DOC] v_缴存业务明细宽表说明
v_缴存业务明细宽表 用于回答缴存明细、缴存金额统计、单位排名、职工缴存情况等问题。
该视图已经封装 t_dw_info、t_gr_info、t_jc_ls 的关联关系。
查询缴存类统计问题时,优先使用 v_缴存业务明细宽表。
月缴存额 = 单位月缴存额 + 个人月缴存额。
视图已经过滤 is_deleted = 0 的无效缴存流水。配套 SQL 问答对:
问题:全市上个月缴存金额排名前十的单位有哪些?
说明:示例以 2026-05-09 作为测试日期,上月为 202604。SELECT
单位账号,
单位名称,
SUM(月缴存额) AS 总缴存额
FROM v_缴存业务明细宽表
WHERE 汇缴月份 = '202604'
GROUP BY 单位账号, 单位名称
ORDER BY 总缴存额 DESC
LIMIT 10;5.4 第二阶段验收标准
第二阶段完成后,至少要验证:
- 原来因为 Join 错导致的错题是否修复。
- 原来因为状态、过滤、指标口径导致的错题是否修复。
- 模型是否优先选择业务视图,而不是继续绕回复杂原表。
- 视图字段是否足够回答目标问题。
- 视图是否没有暴露敏感字段。
- 视图 SQL 是否能在目标数据库直接执行。
六、公司 Git 内部资产:错题集
错题集用于驱动第二阶段视图整理,也用于判断每轮训练是否有效。每次测试发现问题,都要记录在错题集中。
错题集是公司 Git 内部维护资产,不作为上线交付产物,也不导入 Vanna。它的作用是沉淀问题和判断修正方向。只有从错题中提炼出来的修正内容才导入 Vanna,例如补充后的 Documentation、标准 SQL 问答对,或者第二阶段新增的视图 DDL。
建议格式:
问题:
期望结果:
模型生成 SQL:
实际错误:
错误类型:
是否属于高频问题:
修正动作:
修正后的 Documentation / SQL 问答对 / 视图:
复测结果:错误类型建议统一:
| 错误类型 | 表现 | 优先修正方式 |
|---|---|---|
| 表选错 | 查询了不相关表 | 补 Documentation 或 SQL 问答对 |
| 字段选错 | 金额、人数、状态字段不对 | 补字段解释和指标口径 |
| Join 错 | 表关联路径错误 | 先补表关系文档和 SQL 样例,仍不稳定再建视图 |
| 时间错 | 本月、上月、今年理解不一致 | 补时间规则和标准 SQL 样例 |
| 统计错 | 同比、环比、排名、去重错误 | 补 SQL 问答对 |
| 条件漏掉 | 没过滤删除、作废、测试数据 | 补默认规则,必要时写入视图 |
| SQL 不可执行 | 方言、函数、语法不匹配 | 补数据库方言说明和可执行样例 |
七、公司 Git 内部资产:训练记录
训练记录用于记录每一轮往 Vanna 中投喂了什么、验证了什么、留下了什么问题。它是后续维护和回滚的重要依据。
训练记录是公司 Git 内部维护资产,不作为上线交付产物,也不导入 Vanna。它只记录导入清单、版本变化和回归结果,方便后续知道 Vanna 当前能力是怎么形成的。
建议格式:
版本:
日期:
业务域:
阶段:第一阶段实体表训练 / 第二阶段视图整理
本轮新增 DDL:
本轮新增 Documentation:
本轮新增 SQL 问答对:
本轮新增视图:
回归问题数量:
通过数量:
失败数量:
主要失败类型:
修正动作:
遗留问题:
下一轮计划:
负责人:训练记录里要能看出两件事:
- 当前 Vanna 里已经投喂了哪些训练数据。
- 为什么后来新增了某个视图,是因为哪些错题或高频问题驱动的。
八、上线交付验收清单
上线交付只验收 Vanna 中已经生效的训练数据和问答能力。业务建模材料、错题集、训练记录需要保存到公司 Git,但不作为上线交付产物。
上线前至少检查以下内容:
- 第一阶段核心实体表 DDL 是否已经投喂。
- 实体表 Documentation 是否包含字段解释、逻辑表关系、状态枚举、指标口径和时间规则。
- 高频问题是否已经沉淀为 SQL 问答对。
- 是否完成至少 30 个真实问题的回归测试。
- 如果进入第二阶段,视图 DDL、视图说明、视图 SQL 问答对是否已经导入 Vanna。
- 视图是否只暴露必要字段,是否避免敏感字段泄露。
- 生成 SQL 是否能在目标数据库直接执行。
- 是否明确只读权限和查询范围,避免模型生成更新、删除、建表等危险 SQL。
公司内部归档建议同步检查:
- 业务建模材料是否保存到公司 Git。
- 错题集是否保存到公司 Git。
- 训练记录是否保存到公司 Git。
- 是否确认业务建模材料、错题集、训练记录没有作为整份文档导入 Vanna。
建议上线门槛:
| 指标 | 建议标准 |
|---|---|
| 表/视图选择正确率 | 不低于 90% |
| 核心指标口径正确率 | 不低于 95% |
| SQL 可执行率 | 不低于 90% |
| 高频问题结果正确率 | 不低于 85% |
| 敏感字段暴露 | 0 次 |
九、维护原则
后续维护按“先补训练材料,再考虑视图封装”的顺序处理:
- 字段解释不清楚:补 Documentation。
- 指标口径不一致:补 Documentation 和 SQL 问答对。
- 问法复杂但表关系稳定:补 SQL 问答对。
- 表关联关系反复错误:整理业务视图。
- 高频查询重复出现:整理业务视图。
- 业务规则变化:同步更新 Documentation、SQL 问答对、视图和回归问题集。
最终目标是让 Vanna 先理解真实实体表,再用视图治理复杂和易错问题。视图不是第一步的替代品,而是第二阶段针对错题和高频场景的稳定化手段。